

Sztuczna inteligencja coraz częściej pojawia się w aplikacjach mobilnych i webowych. Jeszcze kilka lat temu jej wdrożenie wymagało budowania własnych modeli, trenowania ich na ogromnych zbiorach danych i utrzymywania skomplikowanej infrastruktury. Dziś wygląda to zupełnie inaczej.
W większości przypadków funkcje AI w aplikacji powstają poprzez integrację z gotowymi modelami dostępnymi przez API. Dzięki temu aplikacja może generować treści, analizować dane, prowadzić rozmowę z użytkownikiem czy przetwarzać dokumenty bez konieczności budowania własnego systemu AI.
W praktyce wdrożenie AI w aplikacji opiera się na trzech elementach: integracji z modelem AI, dobrze zaprojektowanych promptach oraz kontroli kosztu tokenów. To one w największym stopniu decydują o tym, czy funkcja AI będzie działać skutecznie i opłacalnie.
W tym artykule pokazujemy, jak działają funkcje AI w aplikacji, ile kosztuje ich wykorzystanie oraz jak wygląda proces wdrożenia.
Dlaczego firmy chcą dodawać AI do aplikacji
W ostatnich latach sztuczna inteligencja stała się jednym z najważniejszych trendów w rozwoju produktów cyfrowych. Coraz więcej firm decyduje się na wdrożenie AI w aplikacji, ponieważ pozwala to automatyzować procesy i zwiększać wartość produktu dla użytkownika.
AI może analizować dane, odpowiadać na pytania użytkowników czy generować raporty bez udziału człowieka. Wyobraź sobie sytuację, w której użytkownik przesyła do aplikacji umowę. Zamiast analizować kilkanaście stron dokumentu samodzielnie, klika przycisk „analizuj”, a funkcja AI w aplikacji wskazuje potencjalne ryzyka i proponuje zmiany.
Modele językowe są także wykorzystywane do generowania treści, np. opisów produktów, materiałów marketingowych czy podsumowań raportów.
AI coraz częściej wspiera również analizę dokumentów i dużych zbiorów danych. Dodatkowo może personalizować doświadczenie użytkownika w aplikacji, dopasowując treści, rekomendacje czy komunikację do jego zachowania.
Jak działa AI w aplikacjach – architektura techniczna
Z punktu widzenia użytkownika funkcje AI w aplikacji wyglądają bardzo prosto – wpisuje się pytanie lub klika przycisk i otrzymuje odpowiedź. Za tym mechanizmem stoi ustalona architektura techniczna.
Najczęściej wygląda ona w następujący sposób:
aplikacja (frontend) → backend → API modelu AI → odpowiedź modelu
W większości nowoczesnych produktów cyfrowych funkcje AI w aplikacji są implementowane właśnie w taki sposób – poprzez integrację z modelami AI przez API i zarządzanie logiką po stronie backendu.
Aplikacja wysyła zapytanie do backendu, który za pomocą wcześniej przygotowanych reguł przygotowuje odpowiedni prompt i przesyła go do modelu AI poprzez API. Model analizuje dane i generuje odpowiedź, która wraca do backendu, a następnie do aplikacji.
Backend pełni tu bardzo ważną rolę.
- Po pierwsze zapewnia bezpieczeństwo kluczy API, które nie powinny być przechowywane bezpośrednio w aplikacji mobilnej lub przeglądarce użytkownika. Klucz API to specjalny identyfikator, który pozwala aplikacji korzystać z modelu AI dostawcy, np. OpenAI lub Google. Jeśli taki klucz znalazłby się bezpośrednio w aplikacji użytkownika, mógłby zostać łatwo przechwycony i wykorzystany przez osoby trzecie do wykonywania zapytań na koszt właściciela systemu.
- Po drugie backend pozwala kontrolować koszty działania AI. Może ograniczać liczbę zapytań, filtrować dane wysyłane do modelu oraz optymalizować prompty.
- Trzecią funkcją backendu jest możliwość przetwarzania danych przed wysłaniem ich do modelu. Aplikacja może np. pobrać informacje z bazy danych, przekształcić je i dopiero wtedy wysłać do modelu AI.
Współcześnie absolutnym standardem pracy z własnymi, prywatnymi danymi firmy (np. przy analizie umów czy w asystentach pracowniczych) jest architektura RAG (Retrieval-Augmented Generation). Model językowy nie jest w stanie “nauczyć się” wszystkich dokumentów firmy na pamięć, a wysyłanie ich w całości przy każdym zapytaniu byłoby skrajnie wolne i kosztowne.
Zamiast tego stosuje się wektorowe bazy danych (Vector DB). Gdy użytkownik zadaje pytanie (np. o konkretny zapis w 100-stronicowym regulaminie), backend za ułamek sekundy przeszukuje bazę wektorową, wyciąga z niej tylko jeden, najbardziej trafny akapit dokumentu i dołącza go do promptu z instrukcją: “Odpowiedz na pytanie użytkownika, bazując wyłącznie na tym dołączonym fragmencie tekstu”. Dzięki architekturze RAG model zyskuje precyzyjny kontekst, koszty użycia tokenów drastycznie spadają, a problem tzw. halucynacji (zmyślania faktów przez AI) zostaje niemal całkowicie wyeliminowany.
W niektórych przypadkach modele mogą działać również lokalnie – na serwerze firmy lub nawet bezpośrednio na urządzeniu użytkownika. Takie rozwiązania stosuje się głównie wtedy, gdy szczególnie ważna jest kontrola nad danymi.
Jeśli planujesz dodać funkcje AI do aplikacji, skontaktuj się z nami, a pomożemy Ci zaprojektować je już na etapie architektury systemu.
Umów się na bezpłatną konsultacjęModele AI używane w aplikacjach
W nowoczesnych aplikacjach AI deweloperzy rzadko ograniczają się do jednego dostawcy modeli. Coraz częściej korzysta się z tzw. agregatorów modeli AI, takich jak OpenRouter, Together AI czy Fal.ai, które udostępniają wiele modeli przez jedno API. Dzięki temu można łatwo porównywać jakość i koszty różnych modeli oraz dynamicznie wybierać najlepszy model dla konkretnego zadania.
Najpopularniejszym rozwiązaniem jest korzystanie z modeli w chmurze przez API. Modele ogólnego przeznaczenia, takie jak chatGPT, Claude czy Gemini oferują szerokie możliwości – od generowania treści i kodu po analizę dokumentów czy multimodalne przetwarzanie danych – dlatego są najczęściej używane w prototypach i produktach, gdzie dane nie są szczególnie wrażliwe.
W projektach wymagających wyższego poziomu bezpieczeństwa danych stosuje się rozwiązania chmurowe z izolowaną infrastrukturą, takie jak Google Vertex AI. Pozwalają one korzystać z modeli AI w prywatnej sieci chmurowej, bez wykorzystywania danych klienta do trenowania modeli.
W organizacjach, które wymagają pełnej kontroli nad danymi, stosuje się natomiast modele uruchamiane lokalnie na własnej infrastrukturze, np. Llama lub Mistral. Takie podejście pozwala zachować maksymalną prywatność danych, choć wymaga większych inwestycji w sprzęt i utrzymanie infrastruktury.
W praktyce coraz częściej stosuje się także architekturę hybrydową: prostsze zapytania obsługuje tańszy model lokalny, a bardziej złożone trafiają do zaawansowanego modelu w chmurze. Pozwala to jednocześnie optymalizować koszty, wydajność i bezpieczeństwo przetwarzania danych.
Przykłady funkcji AI w aplikacjach
- Generowanie treści – AI może przygotowywać opisy produktów, treści na landing page czy materiały marketingowe.
- Chatboty i konwersacje edukacyjne – aplikacja prowadzi rozmowę z użytkownikiem, odpowiada na pytania lub przekazuje wiedzę na określony temat.
- Analiza dokumentów – modele AI potrafią analizować umowy, sprawdzać ich poprawność prawną oraz sugerować zmiany w treści wraz z uzasadnieniem.
- Praca z obrazami i danymi wejściowymi użytkownika – np. w aplikacji “SmartChef” użytkownik podaje składniki dostępne w swojej kuchni, a system generuje propozycje przepisów dopasowanych do tych produktów.
- Wsparcie nauki – AI przyspiesza tworzenie kursów edukacyjnych. Na przykład w “LearnGo” użytkownik zaczyna od wpisania słów kluczowych, a system automatycznie generuje strukturę kursu: opis, tagi, rozdziały i moduły. Dzięki temu nie trzeba ręcznie tworzyć treści – wystarczy dodać materiały lub wideo, a AI przygotowuje resztę.
Prompt engineering – kluczowy element działania AI
Jednym z najważniejszych elementów działania funkcji AI w aplikacjach jest prompt. Prompt to instrukcja wysyłana do modelu AI, która określa, co model powinien zrobić i w jaki sposób ma przygotować odpowiedź.
Dobry prompt składa się zazwyczaj z kilku elementów: określenia roli modelu, kontekstu zadania, danych wejściowych oraz formatu odpowiedzi.
Przykład:
„Jesteś nauczycielem języka angielskiego pomagającym w nauce. Na podstawie poniższego materiału przygotuj 5 fiszek oraz 3 pytania quizowe jednokrotnego wyboru. Używaj prostego języka dostosowanego do osoby początkującej. Odpowiedź zwróć w formacie JSON z podziałem na ‘flashcards’ i ‘quiz’.”
Prompty często dostosowuje się w zależności od rodzaju użytkownika, danych wejściowych czy kontekstu aplikacji. Można np. zmieniać styl odpowiedzi, poziom szczegółowości lub sposób prezentowania wyników.
Projektowanie promptów jest procesem iteracyjnym. Najpierw powstaje pierwsza wersja instrukcji, która jest testowana na różnych przykładach danych. Następnie zespół wprowadza poprawki i ponownie sprawdza wyniki.
Czasami odpowiedni efekt można osiągnąć już po kilku iteracjach. W bardziej złożonych projektach optymalizacja promptów może trwać znacznie dłużej, zwłaszcza gdy funkcja AI rozwijana jest równolegle z całym produktem.
W wielu przypadkach w procesie tworzenia promptów uczestniczą nie tylko programiści, ale również eksperci domenowi, np. prawnicy czy specjaliści zajmujący się edukacją. Ich rolą jest również sprawdzanie, czy odpowiedzi modelu nie zawierają nieodpowiednich sformułowań, czy nie odpowiadają na pytania niezwiązane z tematem oraz czy język jest dopasowany do wieku i kompetencji odbiorców.
Czy administrator może kontrolować działanie AI
W wielu aplikacjach administrator systemu ma możliwość bieżącej kontroli sposobu działania funkcji AI.
Może on zmieniać treść promptów lub parametry modelu, takie jak długość odpowiedzi czy sposób generowania wyników. Dzięki temu działanie AI można dopasować do zmieniających się potrzeb użytkowników oraz optymalizować sposób działania systemu bez konieczności przebudowy całej aplikacji.
Ile kosztuje AI w aplikacji
Warto zacząć od tego, że korzystanie z modeli AI przez API nie działa jak klasyczna subskrypcja znana z narzędzi takich jak ChatGPT czy Gemini. W modelu API płaci się za faktyczne użycie – czyli za każde zapytanie do modelu.
Aby korzystać z API, konieczne jest podpięcie karty płatniczej oraz ustawienie limitów zużycia. Dzięki temu można kontrolować wydatki i uniknąć nieprzewidzianych kosztów.
Każde zapytanie do modelu kosztuje określoną liczbę tokenów. Przykładowo sklep internetowy może używać API do automatycznego generowania opisów produktów na podstawie kilku danych, takich jak nazwa, cechy i parametry. Taki proces może zużyć około 300 tokenów w jednym zapytaniu (np. 120 tokenów w promptcie i 180 w wygenerowanej odpowiedzi), co przy cenach rzędu około 0,25 USD za milion tokenów wejściowych i 2 USD za milion tokenów odpowiedzi daje koszt około $0.00039 za jeden opis produktu. W praktyce oznacza to, że wygenerowanie 1000 opisów kosztowałoby około 0,39 USD, czyli niecałe dwa złote.
Token to najmniejsza jednostka tekstu, którą model AI wykorzystuje do analizy danych. Tokenami mogą być całe słowa, fragmenty słów, liczby lub znaki interpunkcyjne. Na przykład słowo „aplikacja” może zostać podzielone przez model na kilka tokenów.
Modele AI nie analizują więc tekstu w postaci pełnych zdań, ale przetwarzają go właśnie w formie tokenów. Każde zapytanie do modelu obejmuje tokeny wejściowe (czyli treść wysyłaną do modelu) oraz tokeny odpowiedzi generowane przez model.
Przykładowo 1000 tokenów odpowiada w przybliżeniu około 750 słowom tekstu w języku angielskim.
Koszt zapytania zależy więc od liczby tokenów wejściowych i liczby tokenów w odpowiedzi. Typowa operacja w aplikacji może wykorzystywać od kilku do kilkunastu tysięcy tokenów.
Można to porównać do spalania paliwa w samochodzie – wszystko zależy od sposobu użycia.
Jak obniżyć koszty AI w aplikacji nawet 10–20x
Koszty korzystania z AI można znacząco obniżyć dzięki odpowiedniej optymalizacji architektury systemu. Jednym z najprostszych sposobów jest skracanie promptów – im mniej tokenów zawiera zapytanie, tym niższy jest koszt jego przetworzenia. Warto również dobierać model do zadania: w wielu zastosowaniach deweloperskich wystarczą tańsze modele, takie jak Gemini 2.0 Flash czy Mistral Small 3, których koszt zaczyna się od około $0.10 za 1 milion tokenów wejściowych, a dodatkowo często oferują darmowe limity testowe dla nowych użytkowników.
Często stosowaną techniką jest również caching odpowiedzi. Jeśli użytkownicy zadają podobne pytania, system może przechowywać wcześniej wygenerowane odpowiedzi i zwracać je ponownie zamiast wysyłać kolejne zapytanie do API.
W bardziej zaawansowanych systemach stosuje się także pipeline modeli – tańszy model najpierw analizuje zapytanie użytkownika i ocenia jego złożoność, a dopiero w razie potrzeby przekazuje zadanie do bardziej zaawansowanego modelu.
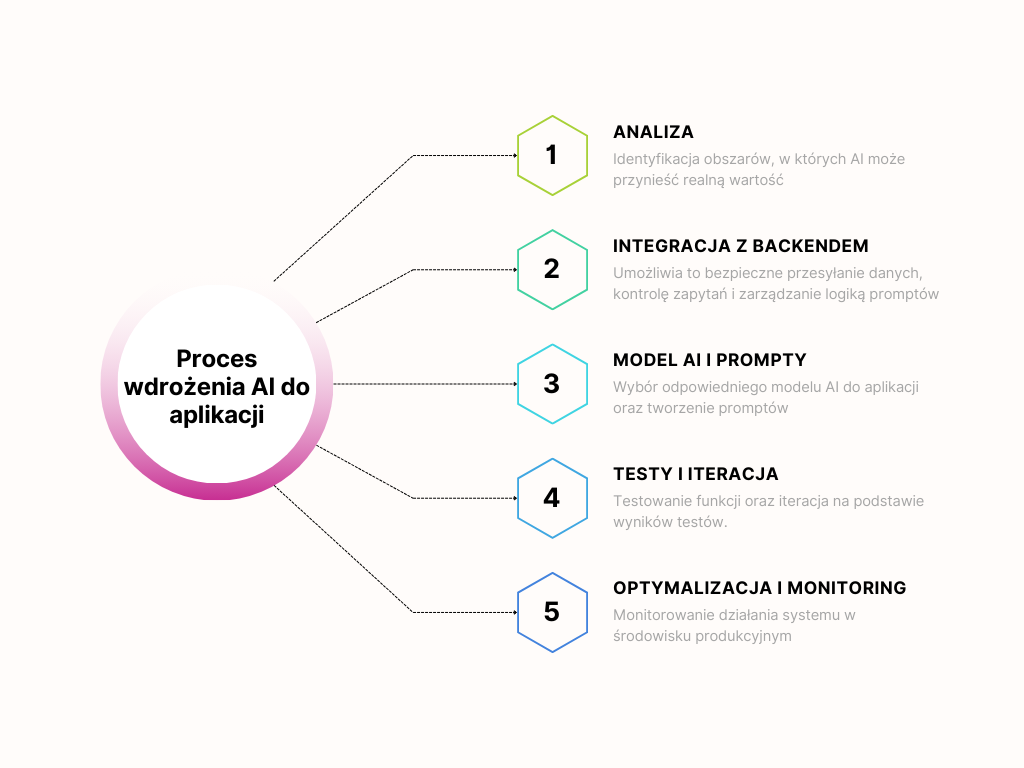
Jak wygląda wdrożenie AI w aplikacji krok po kroku
Proces wdrażania zaczyna się od identyfikacji obszarów, w których sztuczna inteligencja może przynieść realną wartość. Na tym etapie zespół analizuje także, które procesy można zautomatyzować całkowicie, a które tylko częściowo, w kontekście istniejącej logiki produktu.
Kolejnym krokiem jest integracja funkcji AI z backendem aplikacji – to umożliwia bezpieczne przesyłanie danych, kontrolę zapytań i zarządzanie logiką promptów. Dopiero po tym etapie wybiera się odpowiedni model AI, zarówno chmurowy, jak i lokalny (LLM uruchamiany własnym lub wirtualnym serwerze), w zależności od potrzeb dotyczących bezpieczeństwa danych i wydajności.
Następnie prompty i logika działania funkcji AI są tworzone przez zespół składający się z programistów oraz ekspertów domenowych, którzy dbają o poprawność merytoryczną i dopasowanie odpowiedzi do użytkownika. Tworzony jest interfejs użytkownika oraz testowane są pierwsze scenariusze. Po wdrożeniu funkcji przeprowadza się iteracje promptów oraz optymalizację kosztów, a działanie systemu jest monitorowane w środowisku produkcyjnym, aby zapewnić stabilność i maksymalną użyteczność dla użytkowników.
Najczęstsze błędy przy wdrażaniu AI w aplikacji
- brak optymalizacji tokenów – zbyt długie prompty i odpowiedzi zwiększają koszty
- używanie zbyt zaawansowanego modelu do prostych zadań
- brak iteracji promptów – pierwsza wersja rzadko daje dobre wyniki
- źle zaprojektowany UX, który utrudnia korzystanie z funkcji AI
- brak kontroli kosztów i monitorowania wykorzystania API
Informacje o wykorzystaniu API można sprawdzać w panelach administracyjnych dostawców AI.
Przykładowo:
Platforma OpenAI umożliwia monitorowanie wykorzystania API w zakładce „Usage”, gdzie można zobaczyć liczbę tokenów oraz koszt zapytań.
Google AI Studio pozwala z kolei sprawdzić wykorzystanie modeli Gemini oraz limity zapytań.
Podsumowanie
Dodanie funkcji AI do aplikacji nie wymaga dziś budowania modeli od podstaw. W większości przypadków wystarczy integracja z istniejącymi modelami AI oraz dobrze zaprojektowana architektura systemu.
Kluczową rolę odgrywają prompty, które określają sposób działania modelu, oraz kontrola kosztów związanych z przetwarzaniem tokenów.





